memory retrieval with code?
why this might be better than semantic search for your use-case.

In the past year, I’ve implemented two types of memory in LLM by making two types of tools and doing tool calls.
One memory used in Colyap.com is a multi-layered semantic search where in at end of call, the post call analysis on call transcription will store in 4 types of columns and each are embedded and then semantic search against each past call transcript using cosine similarity is done during a live call on LLM’s discretion for type of memory bank it should look for based on user's query, it maybe sometimes look in all 4 memory banks which can be optimized with evals. It works well and for some reasons I feel its better than just doing semantic search on one whole chunk of all call transcriptions. However, this works for a set of areas fit in Colyap’s case and assumption on what people might call in and speak about with Colyap. This is also a little expensive since you might have some redundant calls for embedding but delivers better (essential) user experience. Jury’s still out for how this will scale. Right now it works well for 6 months of user call transcriptions, but imagine a decade. There has to be recency bias then factored in for this.
Recency bias becomes important once memory spans years, because cosine similarity alone treats a highly relevant memory from 2020 and a highly relevant memory from 2025 almost the same, even though in a live call the newer one is usually more likely to reflect the user’s current reality. The way this can work is you don’t replace semantic similarity, you modify the final retrieval score with a time-decay weight. For example, every memory chunk still gets its normal semantic score, say cosine_score = 0.82, but then you multiply or blend it with a recency weight based on how old that memory is. A simple version is exponential decay: recency_weight = e^(-lambda * age_in_days), where lambda controls how aggressively older memories lose priority. So the final score may become something like final_score = cosine_score * recency_weight, or more practically final_score = alpha * cosine_score + beta * recency_weight, because sometimes older memories are still important and you don’t want time to completely disregard older context. If the user mentioned tooth removal in 2020 and again in 2025, both can still show up, but the 2025 memory gets a higher final score unless the 2020 one is semantically much stronger or has a special “durable fact” tag. You can also make the decay different by memory type: preferences and current life context should decay faster, while identity facts, medical history, relationships, business details, or major life events decay slower. This lets the memory system behave less like a dumb vector database and more like a useful assistant that understands that “what matters now” is not always the same as “what was once said.”

What about multiple instances of same event happened in different timestamp- user shared about getting their tooth removed in 2020 and then mentions it again in 2025, semantic search will return both instances with timestamps and that’s fine but what about other context which might be relevant before or after that. Maybe you bring in the whole call transcription raw after semantic search is done on that query. That might work but what about more complicated n-degree connections. Maybe you write your tool so LLM does multiple reads - you mention on call, “my dog, my cat, my car, my last months trip”. Note, let’s say you want to bring in 500 tokens for each chunk and you pass in the top 4 matches that means you’re bringing in 2000 tokens for each topic which might sound not very expensive and it’s not (0.006$ for claude sonnet 4.6) for normal chat sessions, but for voice agents it get’s expensive and increases latency and I’m not sure if you’re using a third party voice provider and you get LLM from them they provide you the discount of prompt caching like the frontier labs does.
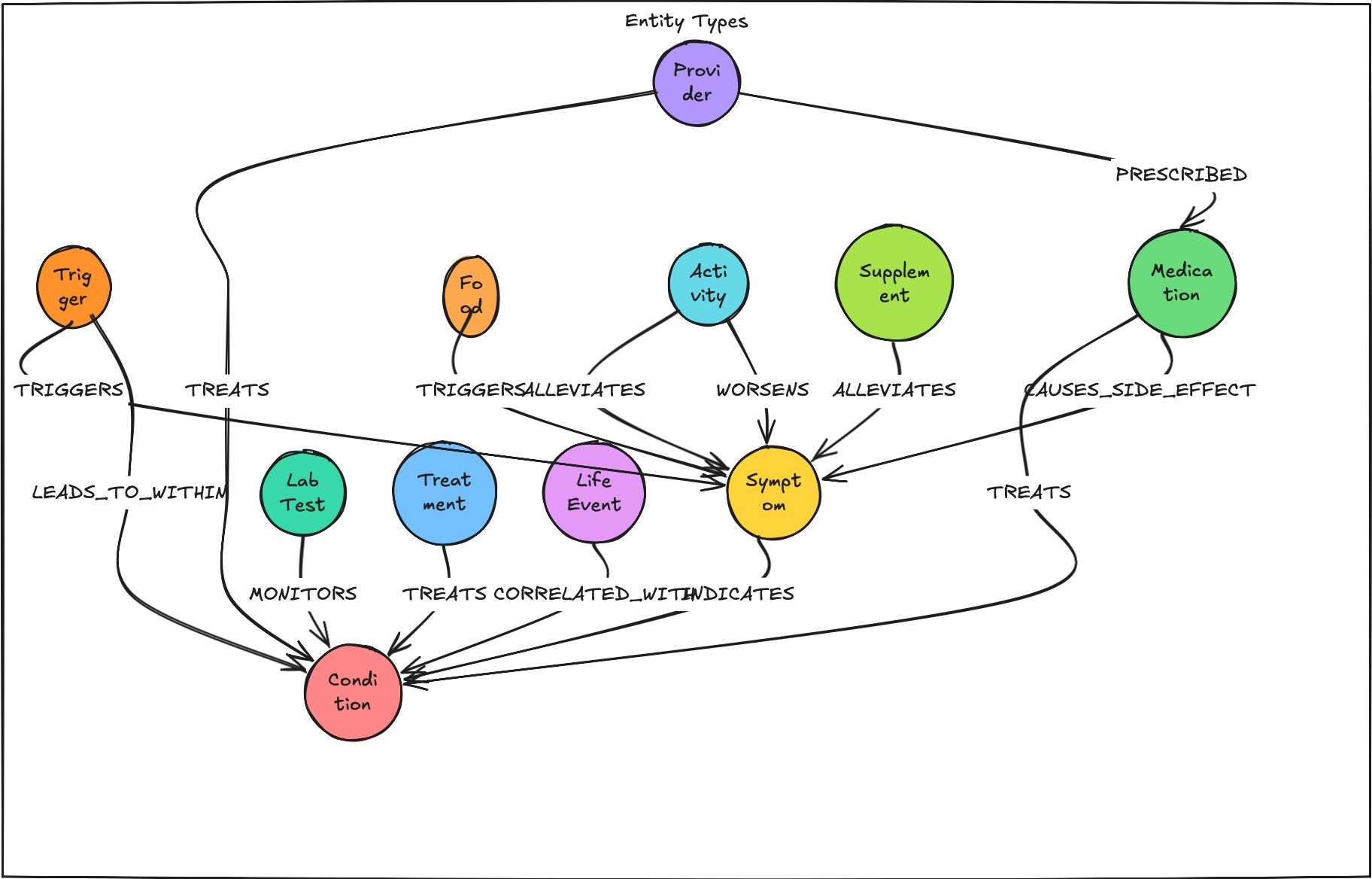
Look at the above health entities diagram if there is a different chunk of conversation which holds one key integral part of information for the LLM to form a whole picture of the problem, how will retrieval work here? This kind of retrieval doesn’t need to be time constrained since there is so many degrees of connections. If I don’t think in terms of the Bitter Lesson, and assume it’s our job to help LLM traverse
The other type of memory we implemented to solve issues for a finance agent we built. The problem you pull in 100,000 rows of financial transactions data from Plaid but you can’t pass it to LLM context so what do you do? Give the LLM your memory as structured JSON, and let it write code to query it.
This works because our financial data from Plaid specially is canonical and non ambiguous.
{
"id": "txn_8f3a2c",
"account_id": "acc_001",
"date": "2026-05-14",
"amount": -82.40,
"name": "Acme Corp",
"merchant": "Acme Cloud Services",
"category": "Software & Cloud",
"type": "debit",
"pending": false,
"channel": "online"
}You give the LLM the schema description, you load the structured JSON, allow the LLM to write code according to what the user wants, give it a sandbox like E2B and let it query your database to get exactly what it wants.
If a user asked: “What were my top 10 vendors last quarter, and which ones grew the most vs. the quarter before?” And you had given it 10 fixed tools to choose from and call those maybe it gets the job done but it has to do that 3-4 tool calls and will do get in more context than needed and you’re trying to make LLM’s be bound more and more by rules. I believe in the philosophy, give it harness, give it direction, give it goal and see it work. That is what code execution is in this case.
df = transactions_df
df["date"] = pd.to_datetime(df["date"])
spend = df[df["amount"] < 0].assign(amount=lambda d: -d["amount"])
q2 = spend[(spend.date >= "2026-04-01") & (spend.date < "2026-07-01")]
q1 = spend[(spend.date >= "2026-01-01") & (spend.date < "2026-04-01")]
top = q2.groupby("merchant")["amount"].sum().nlargest(10)
prev = q1.groupby("merchant")["amount"].sum()
growth = ((top - prev.reindex(top.index).fillna(0))
/ prev.reindex(top.index).replace(0, float("nan"))) * 100
print(pd.DataFrame({"q2_spend": top, "growth_pct": growth.round(1)}))Above example uses Pandas which is in memory but if your data is too big make it write SQL queries in a similar way to your Postgres database.
Code like LLMs even small models can write all day extremely fast, and it can one shot get all relevant rows it needs to answer the user query. One more thing you can do is add a dynamic JSON column, and let LLM go crazy to store random information it get’s there. Well, maybe still add some constraints so it doesn’t become a database nightmare.
What if there is a million rows? Postgres aggregates roughly 1–2 million rows per second per core, and an indexed point lookup takes less than 0.03 ms on decent hardware. With an index on (account_id, date), pulling one user’s slice of a million-row table can be done in milliseconds.
I like the hybrid approach for this, if you’re going to serve millions of users, make it a cache invalidation problem and put hot data in memory and the rest in your database.
I’ve been brainstorming to make a generalized memory solution with code execution, this is what I’ve come up with. Instead of storing memories as free-text blobs (”User mentioned they prefer dark mode... User’s company is Acme...”), store them as a dynamic, typed JSON document the model can query as code:
{
"entities": {
"acme_corp": {
"type": "client",
"facts": {
"industry": "logistics",
"payment_terms": "net_30",
"risk_flag": "pays_late"
},
"relations": {
"invoices": ["inv_201", "inv_245", "inv_267"],
"contacts": ["jane_doe"],
"contracts": ["ctr_44"]
},
"updated_at": "2026-06-01"
}
},
"invoices": {
"inv_245": { "client": "acme_corp", "amount": 12000,
"due": "2026-05-15", "status": "overdue" }
},
"episodes": [
{ "ts": "2026-05-20", "summary": "Negotiated 10% discount with Acme",
"entities": ["acme_corp"], "outcome": "accepted" }
]
}If you structure the schema in a way that is required in your niche. You can build a pretty strong retrieval system. This shall also be the approach if you’re to build a new database from scratch for let’s say a company brain and the company has random emails, pdfs, etc in an unstructured way, you can make a LLM do one pass through all this data and take out important rules, relations, and events by defining the schema by your industry knowledge of what is relevant to extract. I think most companies should do something like this than using out of the box generalized memory solution.
One last memory solution which can be used for extreme speed for extremely small pinned facts and loss in contextual awareness is using a static embedder like Model2VecEmbedder, how it works is that the word "bank" receives the exact same vector in "river bank" and "financial bank". However, I don’t see many use cases for this and that’s why I don’t want to emphasize this.
I wonder like there is SDLC, in the future there should be MDLC (Memory Development Life Cycle): extraction, consolidation, contradiction handling, provenance, recency, decay, permissions, deletion, and evaluation.
Love to hear any insights you have which I might have missed here.